
Teaser: SPGen is a powerful generative model creating consistent 3D shapes with flexible topology from single view images.
Teaser: SPGen is a powerful generative model creating consistent 3D shapes with flexible topology from single view images.
Existing single-view 3D generative models typically adopt multiview diffusion priors to reconstruct object surfaces, yet they remain prone to inter-view inconsistencies and are unable to faithfully represent complex internal structure or nontrivial topologies.
To address these limitations, we propose SPGen, a novel scalable framework that generates high-quality meshes based on multi-layer Spherical Projection (SP) maps. We encode geometry information by projecting it onto a bounding sphere and unwrapping it into a compact and structural multi-layer 2D representation. This SP-based formulation underpins our image-centric generation pipeline and confers three key advantages:
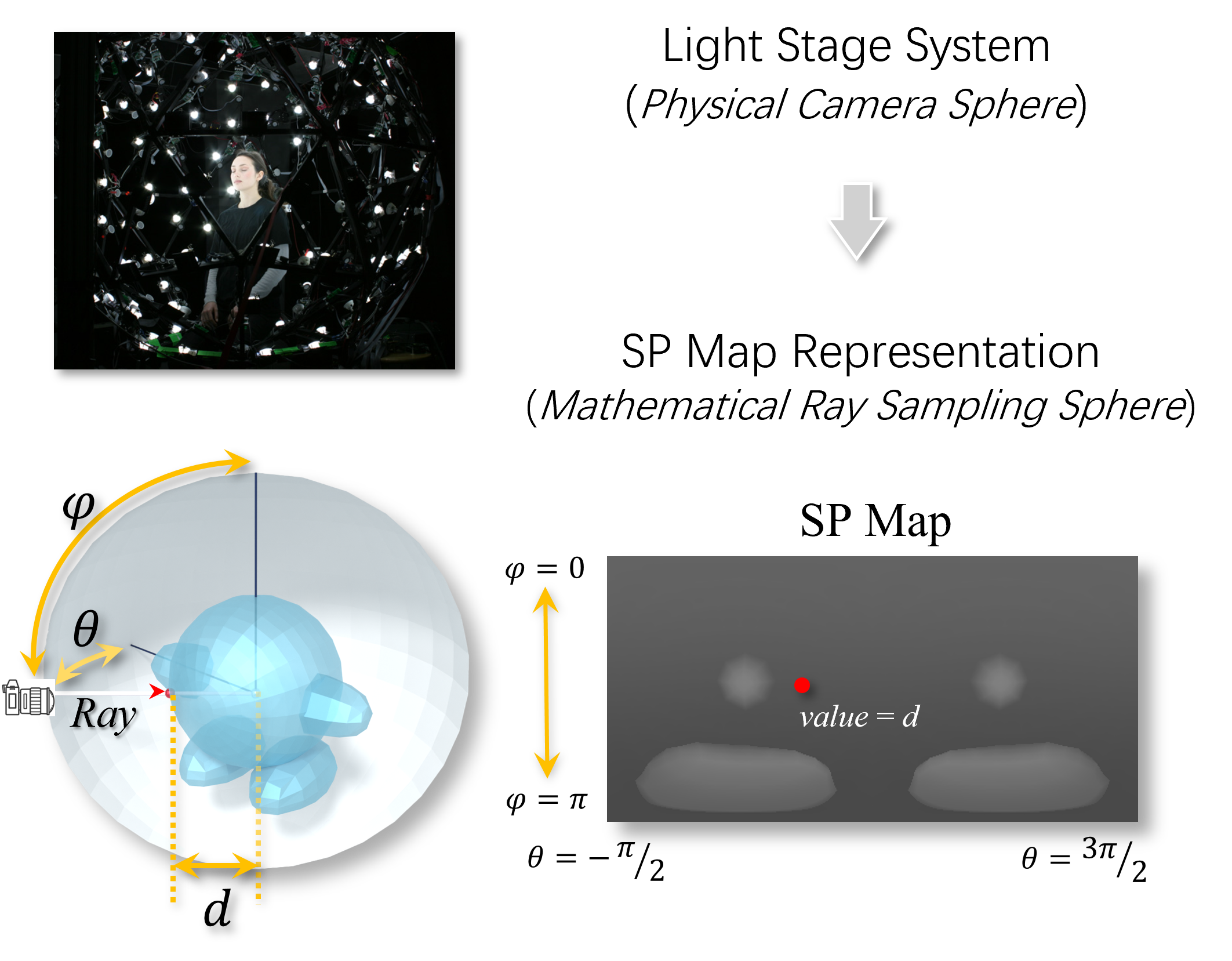
Unlike multi-view images which often suffer from inconsistency, or voxel grids which are computationally heavy, we propose Spherical Projection (SP) maps. We enclose the 3D object within a unit sphere and cast rays from the origin. For each ray, we record the intersection depth. To handle complex topologies (e.g., self-occlusions, internal structures), we trace multiple intersections along each ray and store them in multi-layer SP maps.
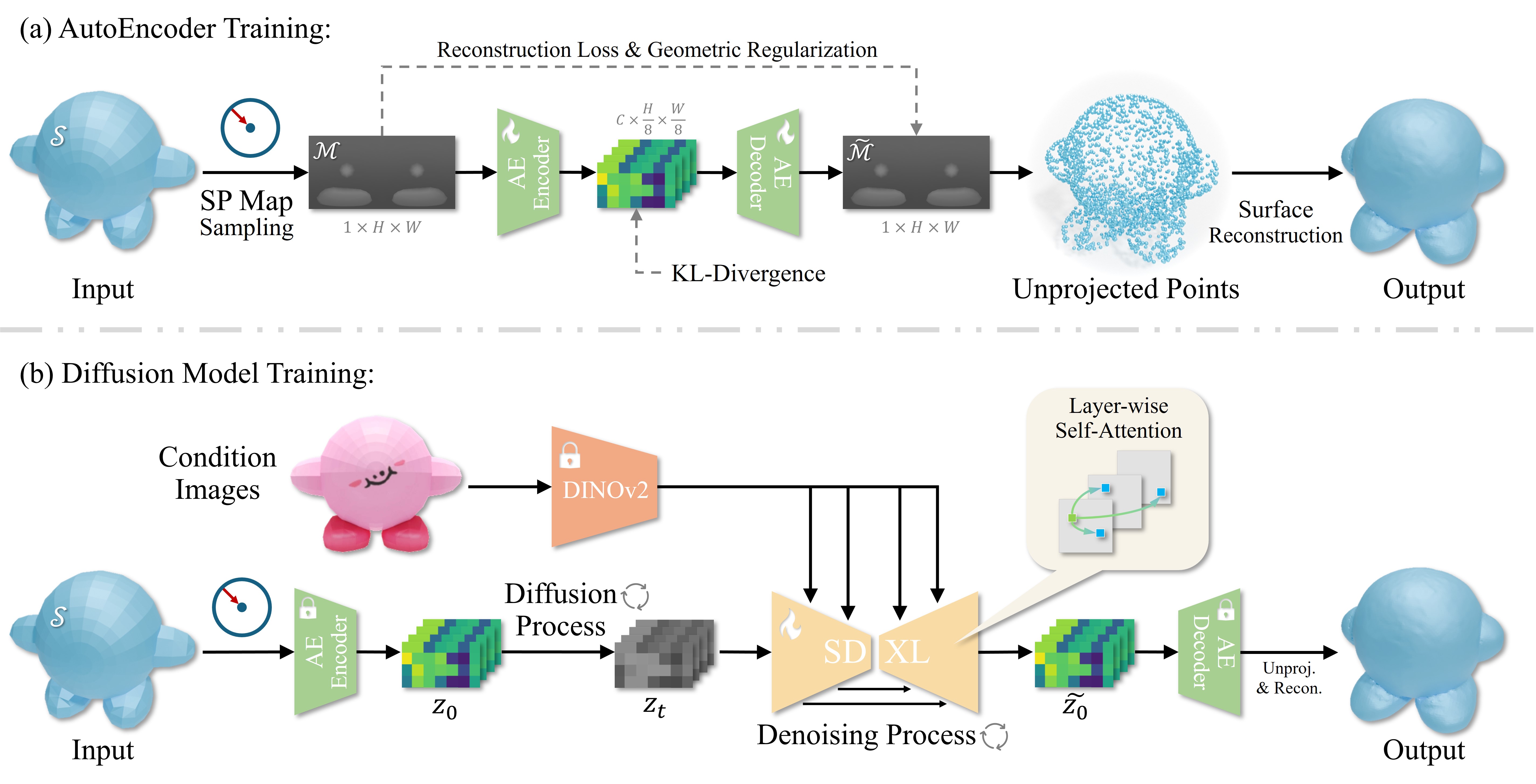
Our pipeline consists of two stages:
(a) AutoEncoder Training: We train a VAE to compress high-resolution multi-layer SP maps into compact latents. We introduce Geometry Regularization (Edge-aware loss & Spectral loss) to preserve high-frequency details.
(b) Diffusion Model Training: We finetune a latent diffusion model (based on SDXL) to generate SP map latents conditioned on a single image. We introduce Layer-wise Self-Attention to ensure alignment between different layers (e.g., ensuring inner structures align with outer shells).
SPGen can reconstruct diverse objects with complex topologies, thin structures, and internal details.

Figure: Generation results on Google Scanned Objects (GSO) and Objaverse.
Compared to geometry-based (e.g., OpenLRM) and multi-view based (e.g., Wonder3D) methods, SPGen yields more consistent geometry and sharper details.


@article{zhang2025spgen,
title={SPGen: Spherical Projection as Consistent and Flexible Representation for Single Image 3D Shape Generation},
author={Zhang, Jingdong and Chen, Weikai and Liu, Yuan and Wang, Jionghao and Yu, Zhengming and Shen, Zhuowen and Yang, Bo and Wang, Wenping and Li, Xin},
journal={arXiv preprint arXiv:2509.12721},
year={2025}
}